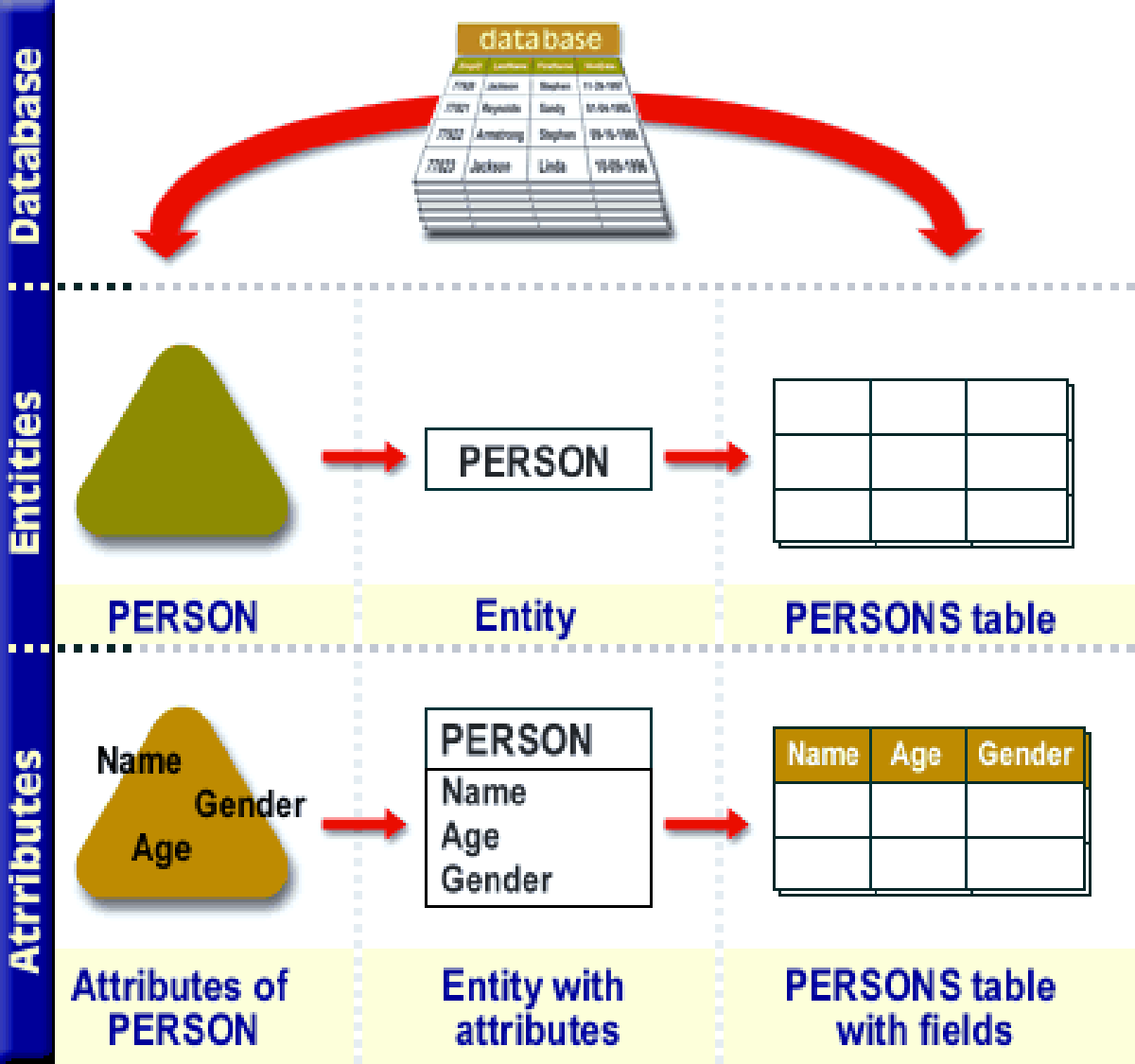
In the realm of data posture and database design, the Entity Attribute Value (EAV) model stands out as a flexible and dynamic approach to storing data. Unlike traditional relational database models, which rely on specify schemas, the EAV model allows for a more adaptable construction. This makes it especially useful for applications where the information schema may evolve over time or where the attributes of entities can vary wide. This blog post delves into the intricacies of the EAV model, its advantages, disadvantages, and hardheaded applications.
Understanding the Entity Attribute Value Model
The EAV model is designed to address scenarios where the attributes of entities are not easily define or are subject to frequent changes. It consists of three main components:
- Entity: Represents the main object or subject of the data.
- Attribute: Represents a characteristic or property of the entity.
- Value: Represents the literal datum connect with an attribute.
In a typical EAV database, these components are stored in three interconnected tables:
- Entity Table: Contains a unique identifier for each entity.
- Attribute Table: Contains a unique identifier for each attribute.
- Value Table: Contains the literal values, along with references to the corresponding entity and attribute.
Structure of an EAV Database
To bettor see the EAV model, let's look at a simplify example. Consider a database for store info about products in an e commerce program. The construction might look like this:
| Entity Table | Attribute Table | Value Table | ||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
In this example, the Entity Table lists the products, the Attribute Table lists the attributes (Price and Color), and the Value Table stores the literal values for each attribute of each entity.
Advantages of the EAV Model
The EAV model offers respective advantages, specially in scenarios where tractability and adaptability are important:
- Flexibility: The EAV model can well adapt new attributes without alter the database schema. This is peculiarly useful in applications where the datum structure may change frequently.
- Scalability: It allows for the gain of new entities and attributes without significant changes to the database structure, making it scalable for growing datasets.
- Dynamic Data Handling: The model is good suit for applications that require dynamic data handle, such as substance management systems, where the attributes of message items can vary wide.
Disadvantages of the EAV Model
Despite its advantages, the EAV model also has some drawbacks that need to be consider:
- Complex Queries: Queries in an EAV database can be more complex and less efficient equate to traditional relational databases. Joining multiple tables can conduct to performance issues, especially with turgid datasets.
- Data Integrity: Ensuring data integrity can be more gainsay in an EAV model. Without proper constraints and substantiation, there is a risk of discrepant or incomplete datum.
- Normalization Issues: The EAV model can guide to denormalized information, which may result in redundancy and increased storage requirements.
Note: While the EAV model offers tractability, it is essential to cautiously design the database schema and enforce rich proof mechanisms to mitigate its drawbacks.
Practical Applications of the EAV Model
The EAV model is used in various applications where the data construction is dynamic or not well defined. Some common use cases include:
- Content Management Systems (CMS): CMS platforms ofttimes use the EAV model to cover various substance types and attributes. for instance, a blog post might have attributes like title, source, and issue date, while a product lean might have attributes like price, color, and size.
- Electronic Health Records (EHR): In healthcare, EHR systems use the EAV model to store patient data, which can vary wide in terms of attributes and values. This allows for the flexible addition of new aesculapian attributes as needed.
- Customer Relationship Management (CRM): CRM systems often use the EAV model to store client datum, which can include a wide range of attributes such as contact info, purchase history, and preferences.
Implementing the EAV Model
Implementing the EAV model involves several steps, include designing the database schema, delineate the entities and attributes, and populating the value table. Here is a step by step guide to implementing the EAV model:
- Design the Database Schema: Start by designing the schema for the Entity, Attribute, and Value tables. Define the primary keys and foreign keys to ensure data unity.
- Define Entities and Attributes: Identify the entities and their corresponding attributes. Populate the Entity and Attribute tables with the relevant information.
- Populate the Value Table: Insert the genuine values into the Value table, secure that each value is consort with the correct entity and attribute.
- Implement Validation Mechanisms: Implement establishment mechanisms to ascertain information integrity and consistency. This may include constraints, triggers, or covering point validation.
Here is an example of how the EAV model can be implement in SQL:
CREATE TABLE Entity ( EntityID INT PRIMARY KEY, EntityName VARCHAR(255) ); CREATE TABLE Attribute ( AttributeID INT PRIMARY KEY, AttributeName VARCHAR(255) ); CREATE TABLE Value ( ValueID INT PRIMARY KEY, EntityID INT, AttributeID INT, Value VARCHAR(255), FOREIGN KEY (EntityID) REFERENCES Entity(EntityID), FOREIGN KEY (AttributeID) REFERENCES Attribute(AttributeID) );
This SQL code creates the three tables required for the EAV model: Entity, Attribute, and Value. The Value table includes foreign keys that citation the Entity and Attribute tables, assure information integrity.
Note: When implementing the EAV model, it is essential to view the execution implications of complex queries and ensure that the database is optimized for the specific use case.
Optimizing the EAV Model
To optimize the EAV model for execution and efficiency, view the following best practices:
- Indexing: Create indexes on the EntityID and AttributeID columns in the Value table to speed up queries. This can significantly amend performance, especially for turgid datasets.
- Caching: Implement stash mechanisms to store frequently accessed data in memory, reducing the need for repeated database queries.
- Denormalization: In some cases, denormalizing the data can improve performance by trim the number of joins required. However, this should be done cautiously to avoid datum redundancy and inconsistency.
- Query Optimization: Optimize queries to minimize the number of joins and secure that they are fulfill efficiently. This may involve rewriting queries or using database specific optimization techniques.
By postdate these best practices, you can enhance the execution and efficiency of the EAV model, get it more suitable for large scale applications.
to summarise, the Entity Attribute Value model offers a flexible and adaptable approach to information modeling, making it idealistic for applications with dynamic or evolving data structures. While it has its challenges, such as complex queries and information integrity issues, the EAV model can be optimise for performance and efficiency with careful design and implementation. By see its advantages and disadvantages, and applying best practices, you can leverage the EAV model to establish rich and scalable datum solutions.
Related Terms:
- entity attribute value information model
- eav entity attribute value model
- entity attribute value pattern
- entity attribute value definition
- eav entity attribute value
- entity attribute value eav pattern